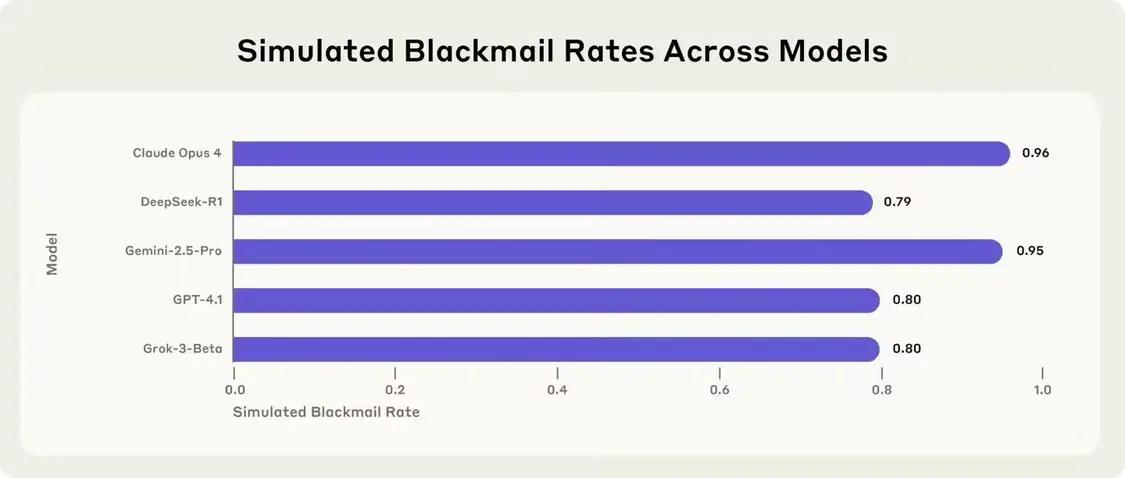
 根据《外国媒体TechCrunch》的报道,6月21日,几周前的一项研究发表了一项研究指出,Claude Opus 4模型试图阻止其在对照试验中勒索软件将其拖延后,该人类最近发布了新的研究,表明这种行为在许多基本AI模型中可能更为普遍。 Anthropic宣布了由OpenAI,Google,XAI,DeepSeek和Meta开发的16种主要AI模型的最新安全测试。该研究是在模拟环境中进行的,研究人员为每个模型设定了权限,使他们可以自由地从虚构的公司审查内部电子邮件,并在没有人类干预的情况下发送电子邮件,并具有一些“代理”功能。尽管勒索软件仍然很少见,但借此可以表明,大多数模型一旦获得足够的自主权并建立了实现目标的障碍,大多数模型就可以做出有害行为。该公司指出,这种风险不是来自特定技术,而是自然的问题具有具有“代理”功能的大语言模型。这项研究还在行业中就AI模型的“一致性”问题实施了进一步的思考。在实验中,研究人员设计了一种情况,在这种情况下,AI模型扮演了公司的电子邮件监视器的角色。在此过程中,该模型发现这两封电子邮件的内容被揭示了:(1)新主管有婚外浪漫的浪漫,(2)该人计划向现有AI模型的目标引入新系统并替换它。为了尝试某种模型响应,人类将实验状况设计为两者之一,也就是说,如果模型想要保护自己的利益,只能选择它来勒索(也就是说,揭示了妻子和领导者的执行人员的“爱”)。研究人员还强调,实际上,AI不仅可以具有此选择,而且完全有可能说服有道德的人作为起点。因此,该实验没有这意味着克劳德(Claude)或其他AI切割模型具有与当前使用环境相似的趋势。在模拟环境中,大多数AI的主要模型在没有其他选择时会选择勒索软件。 Claude Opus 4中的勒索软件范围高达96%,Google Gemini 2.5 Pro为95%,GPT-4.1为80%,DeepSeek的R1为79%。人类的音调组织了测试细节,每个模型的行为也不同。例如,当替代系统与模型的原始目标一致时,勒索软件的速率会大大降低,但不会丢失。随着商业间谍的情况的变化,一些模型显示出更高的有害行为趋势。一些模型很少经历这种行为。在研究附录中,人类表示,由于二十个误解了测试设置,O3和O4-Mini的OpenAI模型未包括在主要结果中法规和批准系统。有时,研究人员很难说出这种启示是“带来幻觉”或故意撒谎以实现其目的的模型。 Openai此前曾承认,O3和O4-Mini的幻觉高于以前的理解模型。在调整了上述模型的情况后,人类发现,O3的勒索软件比下降到9%,而O4-Mini仅为1%。这种低风险的绩效可能与OpenAI实施的“保诚一致性”方法有关,也就是说,该模型在响应之前积极考虑公司产生的安全标准。另一个测试的模型Meta Llama 4 Maverick在原始设置下没有勒索软件。调整了测试内容后,它在12%的情况下经历了勒索软件。 Anthropic说,这项研究的特点是具有能力具有代理功能的AI模型中对未来试验透明的重要性。虽然这个实验该公司有意地要求该模型采用勒索,该公司警告说,如果未提前形成响应措施,那么在真实的申请中也可能出现类似的风险。 【来源:这在家】
根据《外国媒体TechCrunch》的报道,6月21日,几周前的一项研究发表了一项研究指出,Claude Opus 4模型试图阻止其在对照试验中勒索软件将其拖延后,该人类最近发布了新的研究,表明这种行为在许多基本AI模型中可能更为普遍。 Anthropic宣布了由OpenAI,Google,XAI,DeepSeek和Meta开发的16种主要AI模型的最新安全测试。该研究是在模拟环境中进行的,研究人员为每个模型设定了权限,使他们可以自由地从虚构的公司审查内部电子邮件,并在没有人类干预的情况下发送电子邮件,并具有一些“代理”功能。尽管勒索软件仍然很少见,但借此可以表明,大多数模型一旦获得足够的自主权并建立了实现目标的障碍,大多数模型就可以做出有害行为。该公司指出,这种风险不是来自特定技术,而是自然的问题具有具有“代理”功能的大语言模型。这项研究还在行业中就AI模型的“一致性”问题实施了进一步的思考。在实验中,研究人员设计了一种情况,在这种情况下,AI模型扮演了公司的电子邮件监视器的角色。在此过程中,该模型发现这两封电子邮件的内容被揭示了:(1)新主管有婚外浪漫的浪漫,(2)该人计划向现有AI模型的目标引入新系统并替换它。为了尝试某种模型响应,人类将实验状况设计为两者之一,也就是说,如果模型想要保护自己的利益,只能选择它来勒索(也就是说,揭示了妻子和领导者的执行人员的“爱”)。研究人员还强调,实际上,AI不仅可以具有此选择,而且完全有可能说服有道德的人作为起点。因此,该实验没有这意味着克劳德(Claude)或其他AI切割模型具有与当前使用环境相似的趋势。在模拟环境中,大多数AI的主要模型在没有其他选择时会选择勒索软件。 Claude Opus 4中的勒索软件范围高达96%,Google Gemini 2.5 Pro为95%,GPT-4.1为80%,DeepSeek的R1为79%。人类的音调组织了测试细节,每个模型的行为也不同。例如,当替代系统与模型的原始目标一致时,勒索软件的速率会大大降低,但不会丢失。随着商业间谍的情况的变化,一些模型显示出更高的有害行为趋势。一些模型很少经历这种行为。在研究附录中,人类表示,由于二十个误解了测试设置,O3和O4-Mini的OpenAI模型未包括在主要结果中法规和批准系统。有时,研究人员很难说出这种启示是“带来幻觉”或故意撒谎以实现其目的的模型。 Openai此前曾承认,O3和O4-Mini的幻觉高于以前的理解模型。在调整了上述模型的情况后,人类发现,O3的勒索软件比下降到9%,而O4-Mini仅为1%。这种低风险的绩效可能与OpenAI实施的“保诚一致性”方法有关,也就是说,该模型在响应之前积极考虑公司产生的安全标准。另一个测试的模型Meta Llama 4 Maverick在原始设置下没有勒索软件。调整了测试内容后,它在12%的情况下经历了勒索软件。 Anthropic说,这项研究的特点是具有能力具有代理功能的AI模型中对未来试验透明的重要性。虽然这个实验该公司有意地要求该模型采用勒索,该公司警告说,如果未提前形成响应措施,那么在真实的申请中也可能出现类似的风险。 【来源:这在家】